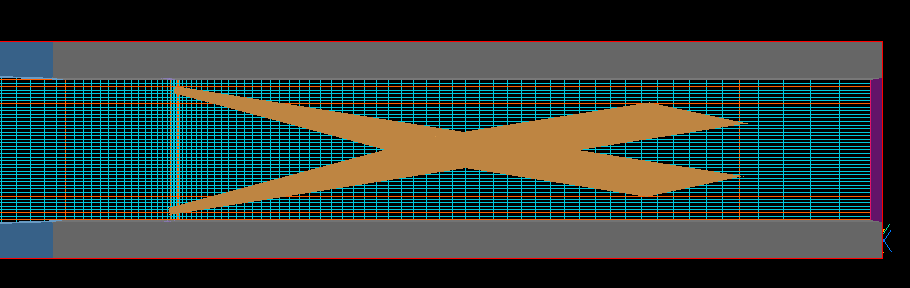
Ver. 3.4で定義されていた,X-wingまわりのメッシュ
・Phoenics3.5導入と初期テスト
先日,(ようやく)Parallel版Phoenics3.5が届いた.導入直後はまともに動かず苦労したが,何とかベンチマークが出来るまでこぎ着けた.その際,以下の事実が判明した.
VR Editor(Parallel版)のリンクファイル(Windows2000/XP)
Ver. 3.4で定義されていた,X-wingまわりのメッシュ

Ver. 3.5のVR Editorで読み込んだら,こんなことに・・・
「Ver. 3.5のVR Editorを信じてはいけない.旧q1ファイルを読み込んだら,かならずメッシュを確認すること.」
*File 1
*X-wing 形状ファイル(Ver. 3.5で正しく動くもの)
10
0.0000E+00 0.0000E+00 0.0000E+00
0.0000E+00 0.0000E+00 1.0000E+00
0.0000E+00 0.2000E+00 1.0000E+00
0.0000E+00 1.0000E+00 0.5300E+00
0.0000E+00 1.0000E+00 0.1600E+00
1.0000E+00 0.0000E+00 0.0000E+00
1.0000E+00 0.0000E+00 1.0000E+00
1.0000E+00 0.2000E+00 1.0000E+00
1.0000E+00 1.0000E+00 0.5300E+00
1.0000E+00 1.0000E+00 0.1600E+00
11
1 2 3 1 130
1 6 7 2 130
1 3 4 1 130
1 4 5 1 130
2 7 8 3 130
4 3 8 9 130
6 8 7 6 130
6 9 8 6 130
6 10 9 6 130
5 4 9 10 130
1 5 10 6 130
*File 2
*X-wing 形状ファイル(Ver. 3.5でエラーになるもの)
10
0.0000E+00 0.0000E+00 0.0000E+00
0.0000E+00 0.0000E+00 1.0000E+00
0.0000E+00 0.2000E+00 1.0000E+00
0.0000E+00 1.0000E+00 0.5300E+00
0.0000E+00 1.0000E+00 0.1600E+00
1.0000E+00 0.0000E+00 0.0000E+00
1.0000E+00 0.0000E+00 1.0000E+00
1.0000E+00 0.2000E+00 1.0000E+00
1.0000E+00 1.0000E+00 0.5300E+00
1.0000E+00 1.0000E+00 0.1600E+00
12
1 2 3 1 130
1 6 7 2 130
1 3 4 1 130
1 4 5 1 130
2 7 8 3 130
4 3 8 9 130
6 8 7 6 130
1 4 9 6 130
6 9 8 6 130
6 10 9 6 130
5 4 9 10 130
1 5 10 6 130
以上の問題をクリヤして,Team COIL標準ベンチマークが実行できるようになった.さて,早速,性能を検証してみよう.q1ファイルは,一度Ver.
3.5のVR Editorで読み込んで,手動で編集する必要があった.リージョンの切り方は自動で決まってしまうので,完全に同じケースではないが,計算時間には影響はないと思われ.
使ったのは,以下の4ノード
Node1,2: Pentium4 2.40GHz RIMM800 512MB
Node3,4: Pentium4 2.80GHz RIMM800 512MB
全nodeのCPU性能を揃えられなかったのは予算の関係.
・パフォーマンス計測
| 実行時間 | 相対性能 | ||||
| 使用node | Ver. 3.4 [s] |
Ver. 3.5 [s] |
Ver. 3.4 | Ver. 3.5 | 3.5/3.4 相対性能 |
| Node1 | 3308 | 3293 | 1.00 | 1.00 | 1.00 |
| Node1+2 | 1925 | 2008 | 1.71 | 1.64 | 0.96 |
| Node1+2+3 | 1614 | 1521 | 2.05 | 2.17 | 1.06 |
| Node1+2+3+4 | 1333 | 1244 | 2.48 | 2.67 | 1.07 |
Ver. 3.5の方が性能が高い.特に,node数が増えると差が顕著に表れる.アルゴリズムを改善したようだ.
2ノードのときだけ性能が逆転しているが,理由はわからない.観察される現象としては,計算中のestimated
timeは1860s程度なのに,ループ終了してからの,最後のdata collectionが異常に長い.2ノードのときだけ,特別時間がかかるアルゴリズムになっているのか?
また,4ノード時のefficiencyにも注目.Ver. 3.4の2.48に比べ,2.67と相当改善している.efficiencyは67%と出た.
・計算結果の比較
ベンチマークは計算を500ループで打ち切っているが,ループ回数を3,000に変更,収束するまで計算させてから比較を行った.
計算収束の状況
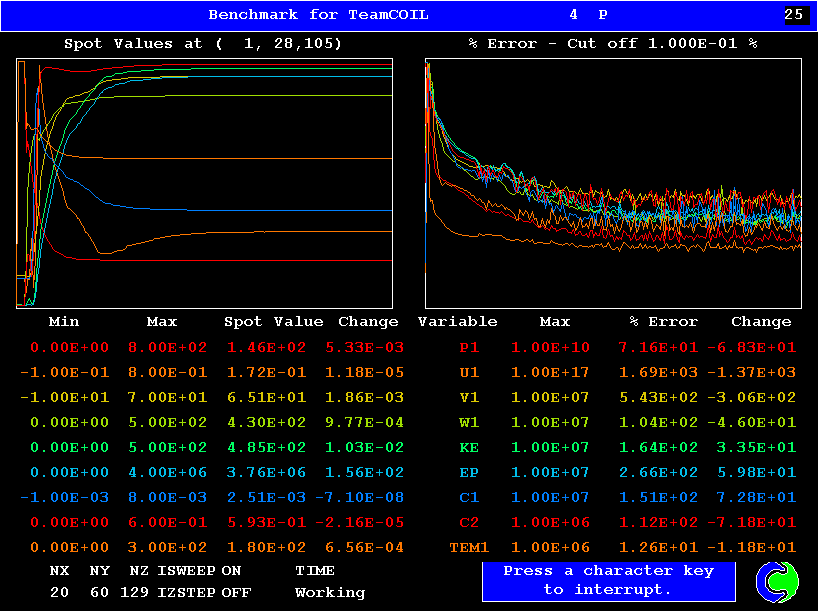 Ver. 3.4
Ver. 3.4
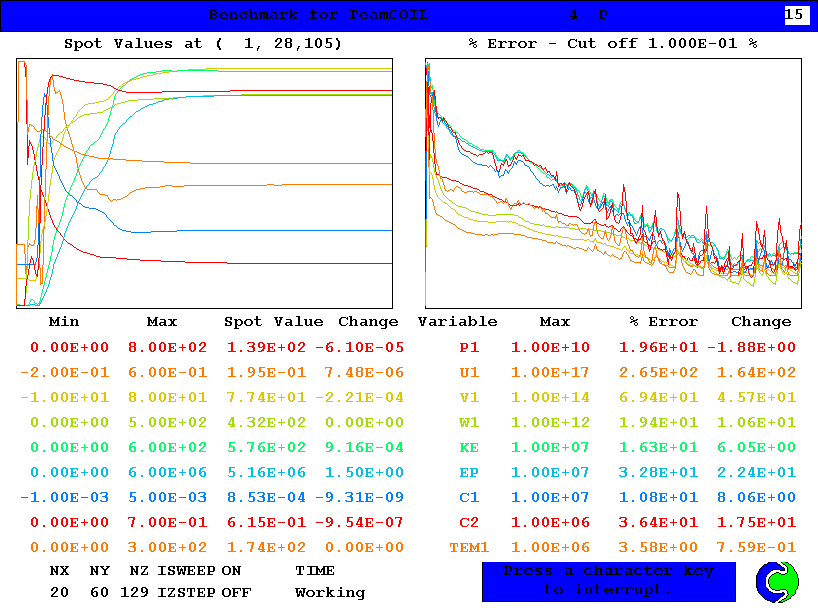 Ver. 3.5
Ver. 3.5
(Ver. 3.5が白地なのはプログラム仕様です)
ダクト中央の主な変数値
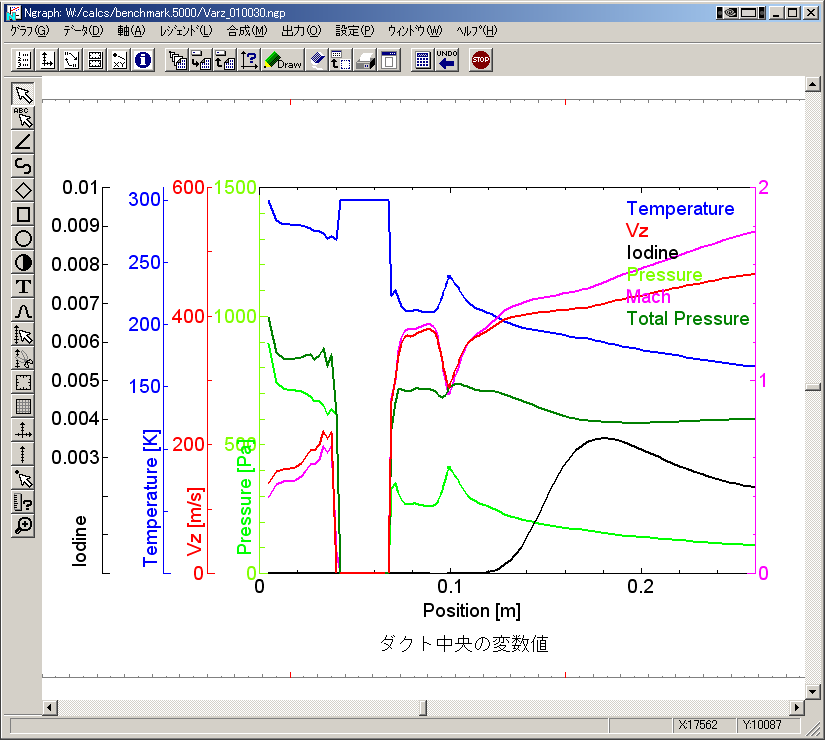 Ver. 3.4
Ver. 3.4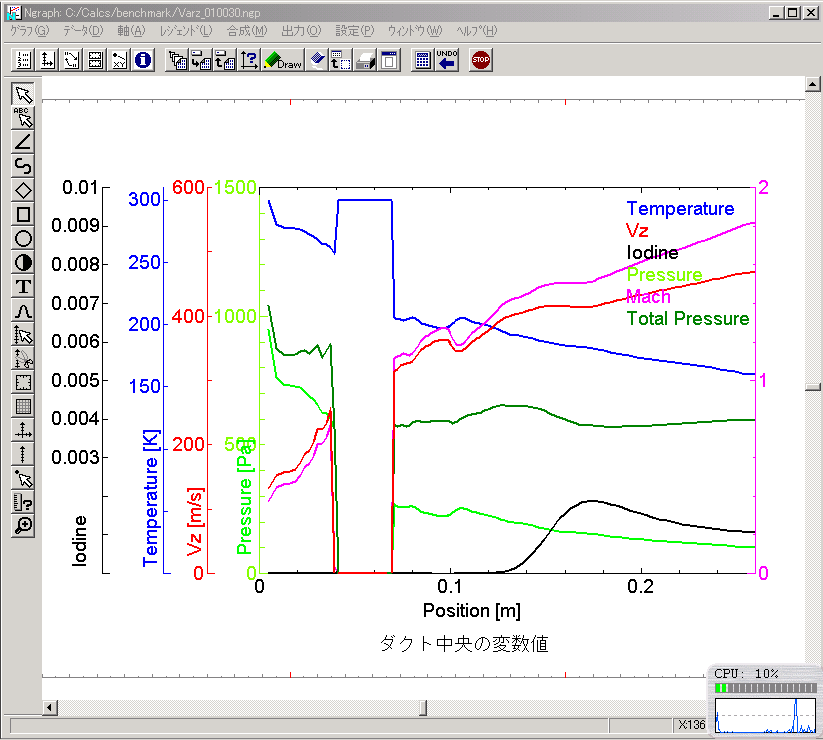 Ver. 3.5
Ver. 3.5
流速(W)分布の比較
 Ver. 3.4
Ver. 3.4
 Ver. 3.5
Ver. 3.5
流速(W)分布の比較(ダクト中央) ----Ver. 3.5 ----Ver. 3.4
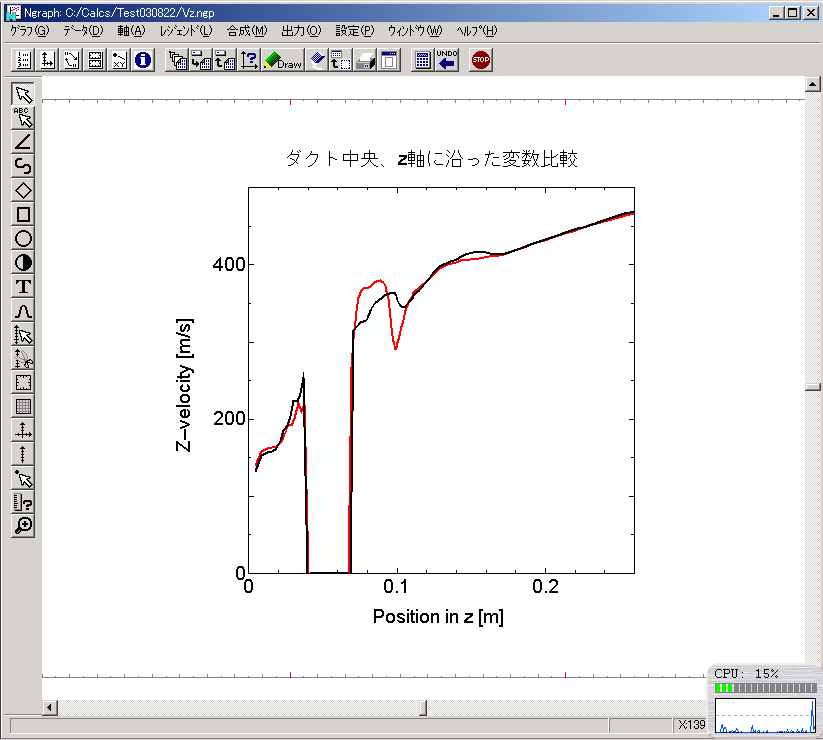
静圧(P1)の比較(ダクト中央) ----Ver. 3.5 ----Ver. 3.4
計算の収束性は,Ver. 3.5の方が遙かに良い.これは,非常に歓迎するべき改良である.今まで,我々の計算は何となく収束しないケースが多かったので.計算結果の一致は必ずしも完璧とは言えないが,これはVer.
3.4の計算が収束状態になっていないので,一致しないことの方が当然である.流れが層流になっている,下流部分についてはVer.
3.4とVer. 3.5が完全に一致しており,この点からは両者の結果は整合していると判断できる.
・まとめ
