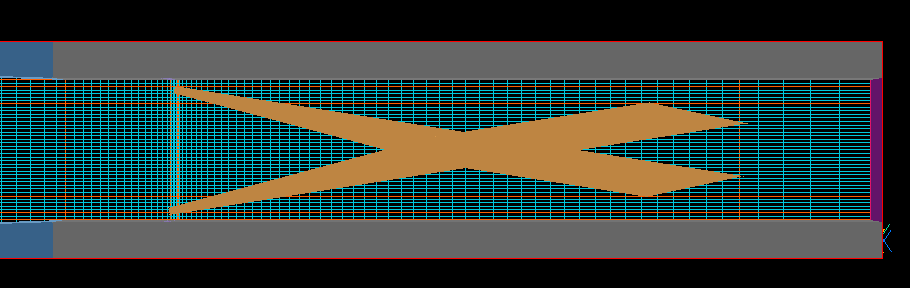
Ver. 3.5で定義されていた,X-wingまわりのメッシュ
・Phoenics3.6.1導入と初期テスト
V3.5のリリースから2年余り,その間Single版は2度のバージョンアップを経たが,ようやくParallel版が追いついた.Single版の最新版と同等のPhoenics3.6.1が届いたので早速テストしてみた.3.6.1は3.5のParallel版と大きく異なる点が二つある.
そして,ベンチマークファイルを走らせようと試みて気がついた点が二つ.
Ver. 3.5で定義されていた,X-wingまわりのメッシュ
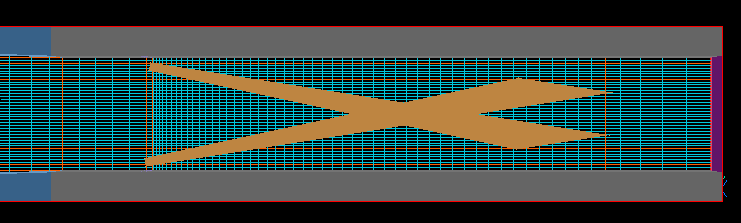
Ver. 3.6.1のVR Editorで読み込んだら,こんなことに・・・
手動で修正し,ベンチマークテストを行って3.5とパフォーマンスを比較した.
使ったのは,以下の4ノード
Node1: Pentium4 2.40GHz RIMM800 512MB
Node2: Pentium4 3.06GHz RIMM800 512MB ※3.5テスト時からグレードアップした.
Node3,4: Pentium4 2.80GHz RIMM800 512MB
全nodeのCPU性能を揃えられなかったのは予算の関係.
・パフォーマンス計測(PASOL=offで比較)
| 実行時間 | 相対性能 | ||||||
| 使用node | Ver. 3.4 [s] |
Ver. 3.5 [s] |
Ver. 3.6.1 [s] |
Ver. 3.4 | Ver. 3.5 | Ver. 3.6.1 | 3.6.1/3.5 相対性能 |
| Node1 | 3308 | 3293 | 2395 | 1.00 | 1.00 | 1.38 | 1.38 |
| Node1+2※ | 1925 | 2008 | 2329 | 1.71 | 1.64 | 1.42 | 0.87 |
| Node1+2+3 | 1614 | 1521 | 3733 | 2.05 | 2.17 | 0.89 | 0.41 |
| Node1+2+3+4 | 1333 | 1244 | 2429 | 2.48 | 2.67 | 1.36 | 0.51 |
※3.6.1テストのみ,Node2の性能が高いので,より公平な比較のためNode1+Node3で計算.
単一ノードのばあいの計算速度は3.6.1の圧勝である.これは,3.6.1でSingleとParallelの実行ファイルが統合されたせい.3.5のSingle版とParallel版単一ノードの計算性能は体感的に倍ちかく異なるが,3.6.1のばあいはSingleノードとParallel単一ノードの性能に全く差は無かった.
2ノードのときの性能は大分落ちている.87%はきついなあ.
Ver. 3.6.1の3ノード,4ノードの計算で極端にパフォーマンスが落ちている.これについては後述.
・パフォーマンス計測(PASOL=on/offの比較)
| 実行時間 | |||
| 使用node | PASOL off [s] |
PASOL on [s] |
PASOL on/off 相対実行時間 |
| Node1 | 2395 | 3743 | 1.56 |
| Node1+3 | 2329 | 2910 | 1.25 |
| Node1+2+3 | 3733 | 3895 | 1.04 |
| Node1+2+3+4 | 2429 | 3157 | 1.30 |
1ノード,PASOL=onの3743sは時間がかかりすぎ.理由はわからない.2ノード時のon/off比1.25はカタログ通り.Node数を変えるとPASOL=on/off比が変わるのは,おそらくたまたまPartial
solidが多いノードに性能が引きずられるからではないか.まあ,on/off比を1.25とすると,Ver
3.5から3.6.1に変わったことで,PASOLの効果も含めて実行時間はほぼ1.5倍になることがわかる.
・計算結果の比較
ベンチマークは計算を500ループで打ち切っているが,ループ回数を3,000に変更,収束するまで計算させてから比較を行った.
計算収束の状況
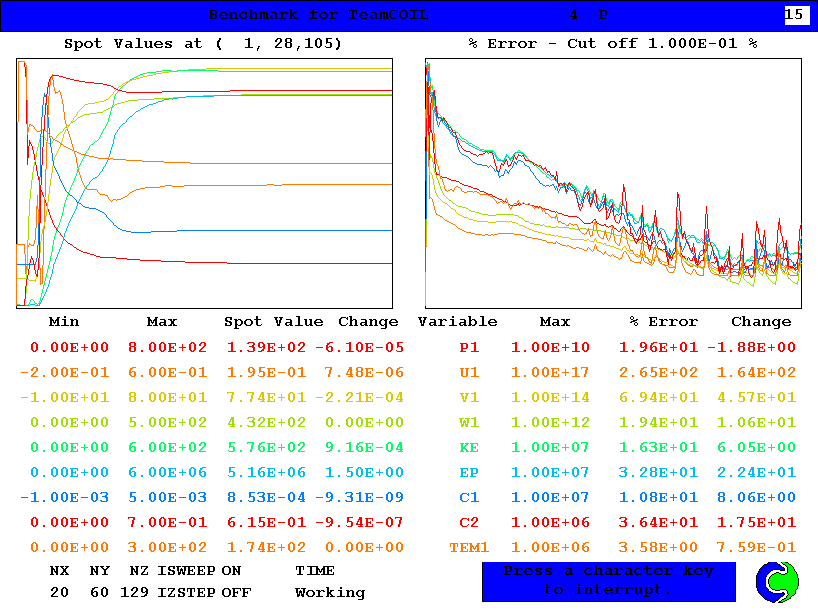 Ver. 3.5
Ver. 3.5
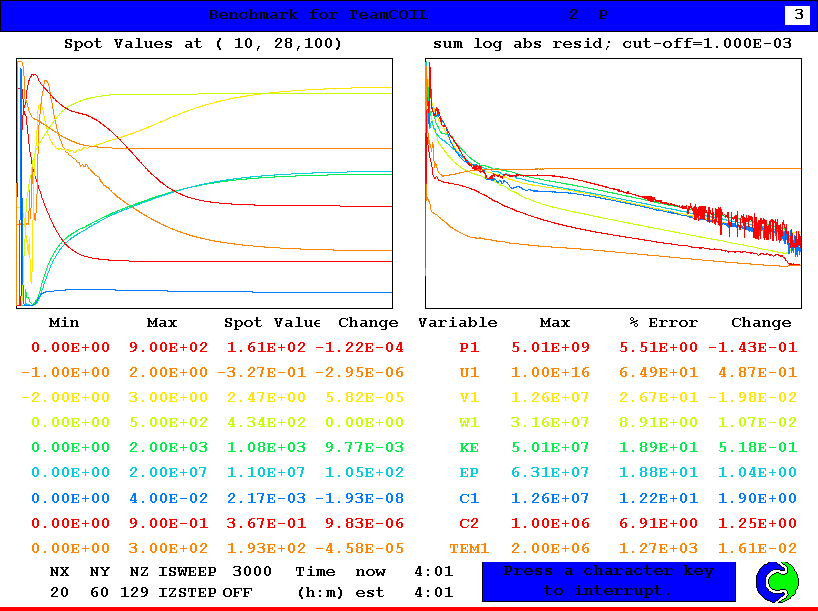 Ver. 3.6.1
Ver. 3.6.1
Ver. 3.6.1はPASOL=onで計算している.明らかに,温度の収束性が悪い.
ダクト中央(x=10,y=30)の主な変数値
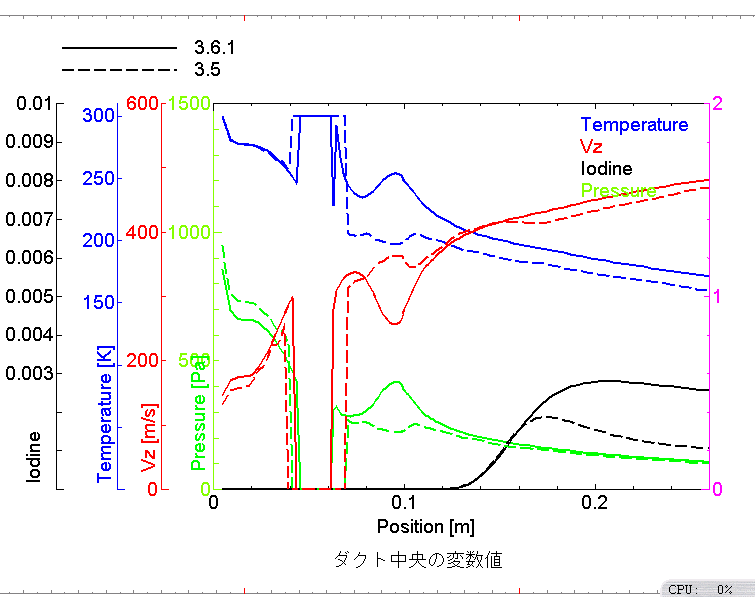
今回の比較はバージョンの違いと言うよりは,PASOLの効果を見るような形となっている.X-wingのケースにおいて,PASOLがどのような効果を発揮するかは既に検証しているので多くは語らない.少なくとも,上の結果から言えることは,ざっくりした近似では両者に違いはない,ということだ.沃素濃度分布が大きく異なるように見えるが,これは主流に垂直な面内での僅かな位置の違いで大きくぶれるので,あるライン上で大きく違っていてもどうと言うことはない.
・マルチノード計算の性能低下について
今回,ベンチマークのケースにおいて3,4ノードの性能が極端に悪い,と言う結果を得た.CHAM社に問い合わせたが,原因はわからないという.現在のところ判明しているのは
絶望感にうちひしがれていたが,たまたま行った,最新のX-wingのケース(40 x
103 x 304)ではノード増加に伴い連続的に性能が上がっていることを発見.分割方法は同じなのになぜだろう.どうやら,ベンチマークの,y方向のグリッド60,というのがマジックナンバーなのではないだろうか.
試しに,以下の4つのケース
の性能をノード数の関数でグラフにしてみた.
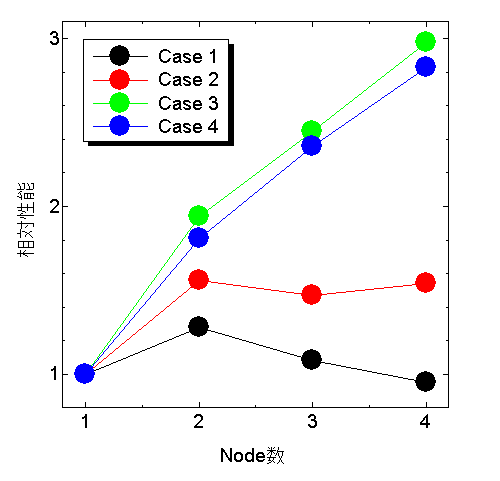
こうしてみると,最新版X-wing(Case 3)とV101(Case 4)では真っ当に性能が出ているが,今までのベンチマークではダメダメということがよくわかる.理由は分からないが,当面は困らないのでこのまま放置.
※特筆するべきは,Case3,4において4ノードで1ノードの3倍の性能が出ている,ということ.Ver. 3.5ではSingle版の性能はParallel 1ノードの1.4倍ほどだったので,結果的Ver. 3.6.1は3.5に比べて1.4倍程度のパフォーマンス向上を得た,と言うことになる.ヒャッホー!
・まとめ
